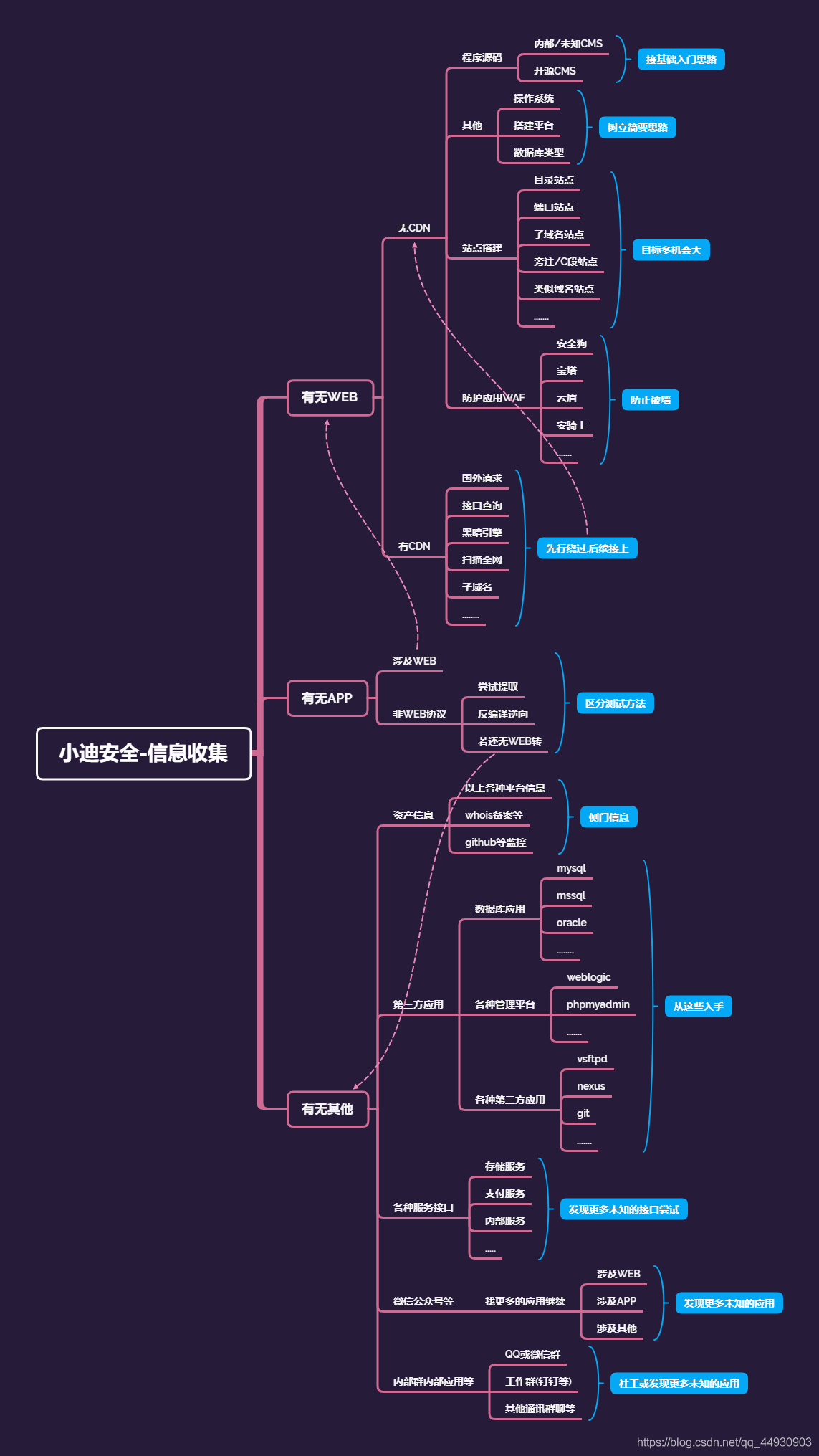
安全信息收集信息收集——资产监控拓展
Yatming的博客信息收集——资产监控拓展

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
import requests
import json
import time
import os
import pandas as pd
time_sleep = 20
while (True):
headers1 = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome / 70.0.3538.25 Safari / 537.36 Core / 1.70.3741.400 QQBrowser / 10.5.3863.400 "}
datas = []
response1 = None
response2 = None
if os.path.exists("olddata.csv"):
df = pd.read_csv("olddata.csv", header = None)
datas = df.where(df.notnull(), None).values.tolist()
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url = "https://api.github.com/search/repositories?q=CVE2020&sort=updated&per_page=10", headers = headers1, verify = False)
response2 = requests.get(url = "https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10", hea ders = headers1, verify = False)
else:
datas = []
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url = "https://api.github.com/search/repositories?q=CVE2020&sort=updated&order=desc", headers = headers1, verify = False)
response2 = requests.get(url = "https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc", heade rs = headers1, verify = False)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"], data2["items"]]: for i in j: s = {
"name": i['name'],
"html": i['html_url'],
"description": i['description']
}
s1 = [i['name'], i['html_url'], i['description']]
if s1 not in datas:
params = {
"text":s["name"],
"desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"])
}
print("当前推送为"+str(s)+"\n")
requests.packages.urllib3.disable_warnings()
requests.get(url = "https://sc.ftqq.com/SCU101248T******.send", params = params, headers = headers1, timhout = 10, verify = False)
time.sleep(1)
print("推送完成!\n")
datas.append(s1)
else:
pass
print("数据已在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)
|
在一些网站的最下方,一般会有一些链接导航之类的,这些导航有很大的可能性是目标网站的子域名
信息收集还有一个切入点,就是从网站的备案信息如上,上几章说的是用备案信息做一些关联和验证,还有一种就是,有些网站可以在站长之家的whois查询,找到网站备案人,那么就可以用网站的备案人来反查这个备案人注册了哪些网站,这也是一个切入点。如果不能直接在网站的备案号那里找到网站的备案人信息,可以用 “天眼查” 等一些网站来查询这个网站的 “法人”
IP对应域名,域名对应IP地址,但是有的时候一个IP地址对应多个域名,那么这个时候就可以通过IP反查域名,或者域名反查IP,这同样也是一个切入点
如果你在黑引擎进行,搜索的时候,如果在地区这里有很一些国外的地区的话,那么就需要考虑一下了,比如说就是如果就是中国的一个普通的大学,然后在美国有信息,还有其他国家也有,那么就可以直接屏蔽掉这些国家的信息,因为这个是因为在这个国外的网站中可能有一些相关信息,然后这个黑暗引擎又刚好爬到了这个信息,然后就会对这个国外的网站进行收录